OpenAI Whisper APIを試す

OpenAI Whisper APIを使って音声ファイルから文字の書き起こしをやってました。
Pythonから呼び出し
openai.Audio.transcribeを使っ文字起しを行いますが、今回は単純なのでコードのみ示します。
#!/usr/bin/env python # -*- coding: utf-8 -*- # OpenAI Whisper APIを呼び出し、指定された音声ファイルから文字の書き起こしを行う。 # 使い方: transcribe input.mp3 # 必要モジュールのインポート import sys import os from dotenv import load_dotenv import click import openai # コマンドライン引数の設定 @click.command() @click.argument('audio_file', type=click.Path(exists=True)) @click.option('--verbose', '-v',is_flag=True, help='Verbose mode') def transcribe(audio_file,verbose): """This tool summarize test from stdin""" # .envからAPIキーを取得する。 # .envファイルには、OPENAI_API_KEY_="APIキー"のように記載する。 load_dotenv() openai.organization = os.environ["OPENAI_ORGANIZATION_ID"] openai.api_key = os.environ["OPENAI_API_KEY"] # チェックするテキストの取得 audio = open(audio_file, 'rb') transcript = openai.Audio.transcribe('whisper-1', file=audio, speaker_labels=True, verbose=verbose, language='ja' ) click.echo(transcript['text']) if __name__ == '__main__': transcribe()
文字起ししてみた
実際に音声ファイルを使って呼び出してみた例です。
openai.Audio.transcribe呼び出すと、JSONでテキストが返ってきますが、"text"という項目しかありません。
取り出すと以下のようなプレーンなテキストを取得できます。
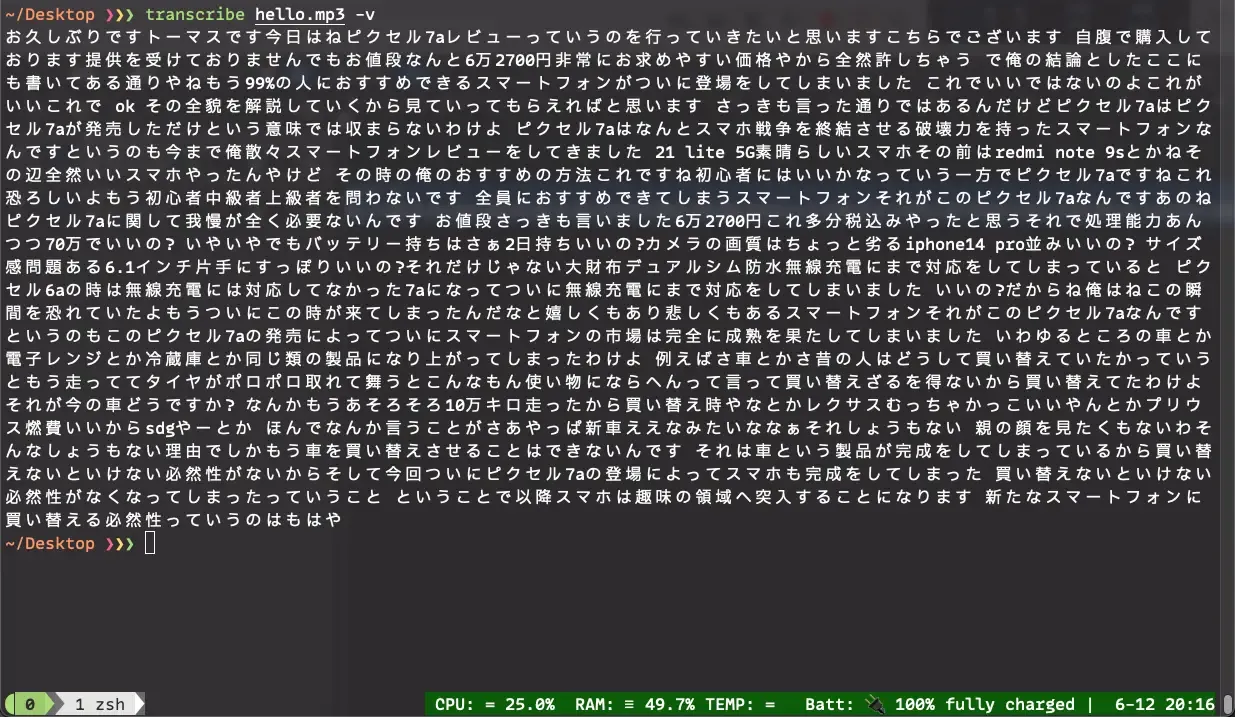
文字起し例
ここからいろいろ加工すればよいのでしょうが、素直にsrt形式などでも出力できる Whisper CLIを使ったほうが便利ではあります。
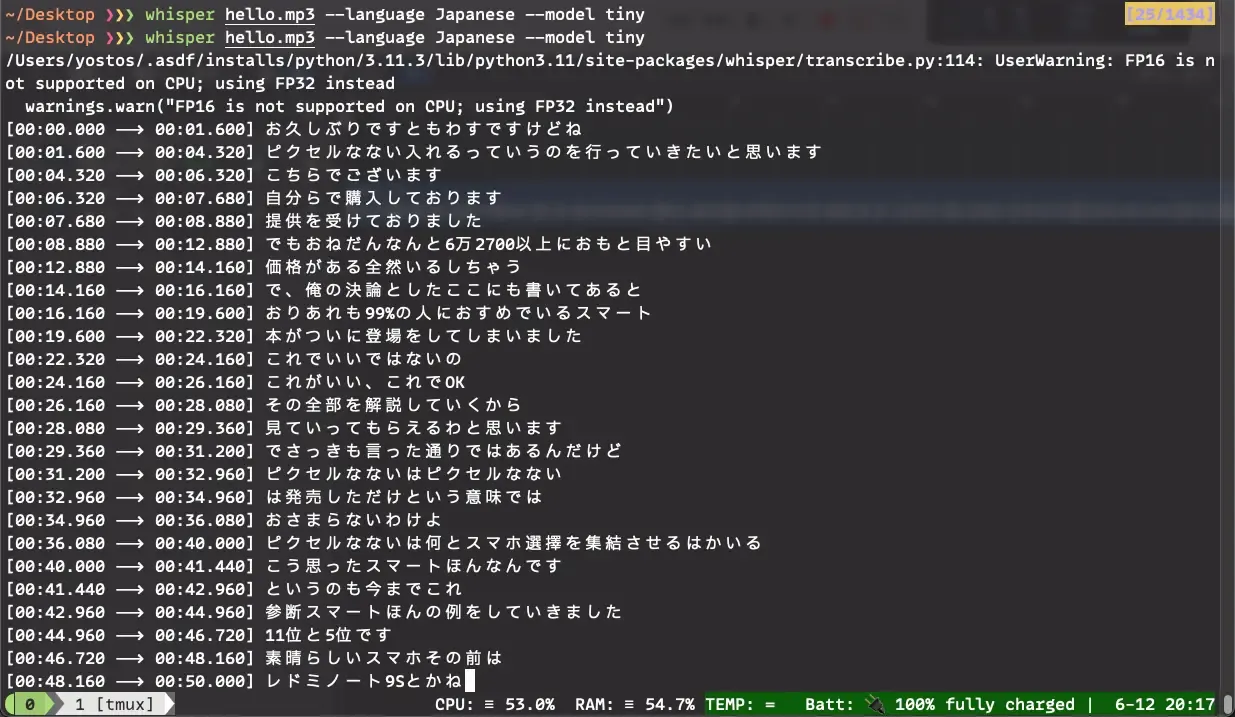
Whisper CLI:文字起し例