PDFのフォントに関する色々

今担当しているプロジェクトでPDFで表示されるフォントがちょっと問題になりました。
古いPDF生成のプログラムを新しいライブラリで作り直したところ表示されるフォントが変わってしまったと言うものです。色々調べて結果、今週だけはPDFやフォントの知識が上がっているのでまとめておきます。
PDFでどんな文字の字形が変わってしまったか?
その古いPDF生成プログラムでは、 PDFBox1.8を使用してPDFを作成していました。
試しに問題のあった文字についてPDFBox1.8を使って表示させてみた例が以下の画像です。 (ソースコードは、 GitHub で公開しています)

PDFBox1.8での漢字表示
新しく作成したプログラムでは以下のように表示されます。

新しいプログラムでの漢字表示
どうも文字の字形が変わってしまっているのは、JIS2004で字形が変わった文字のようでした。 しかも古いプログラムの字形はJIS2004以前のものが表示されています。
新しいプログラムではフォント埋め込みを使っており、JIS2004で改訂があった文字は ちゃんとJIS2004のグリフで表示されてます。
フォントが問題なのか?
新しいプログラムでは、IPAフォントをPDFにサブセット埋め込みで使用する予定でしたが、 もしかしたら古いプログラムでは古いフォントが使用されるのかと確認してみました。 Adobe Readerのプロパティから確認すると以下のようになっています。
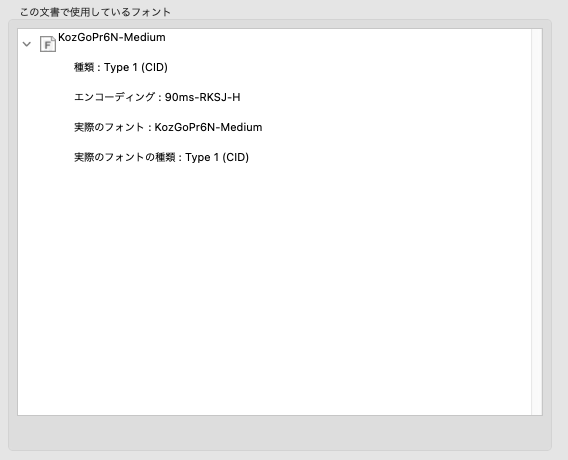
古いプログラムで生成したPDFのフォント設定
古いプログラムで生成したPDFはAdobeの小塚フォントが指定されています。ただし、フォントは 埋め込みでありません。フォントがサポートする文字を調べてみました。
ちなみにフォントはサポートする 文字集合 と グリフ によりどのような文字を表示できるかが決まります。
文字集合については、日本では日本産業企画(JIS)で符号化文字の規格が定められており、 現在は一般的に JIS X 0213が使用されています。いわゆる非漢字、第1、第2水準漢字に 第3、第4水準漢字を含めたものです。
グリフについても、JISで規格化されており、「例示字形」として定義されています。 文字集合のJIS X 0213が策定された2000年当時はグリフは古いJIS90のままだったので、JIS X 0213:2000と呼ばれています。 2004年にグリフの改訂があり現在は JIS X 0213:2004と呼ばれています。
2004年のグリフの改訂は、それまでビットマップであっため印刷標準字形と異なっていた 一部の文字の字形を印刷標準字形にあわせたと言うものです。
まとめと下表のようになります。
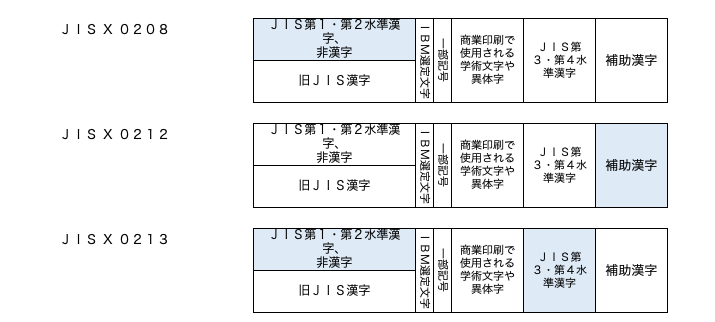
文字集合についてのJIS規格
また、DTPの世界ではJIS企画以前からAdobeがフォントの開発を行っていた経緯もあり、 Adobeは独自の文字集合とグリフの定義を持っています。以下がAdobeの定義です。 商品呼称の末尾に「N」と付くものは、グリフがJIS2004に従ったものです。
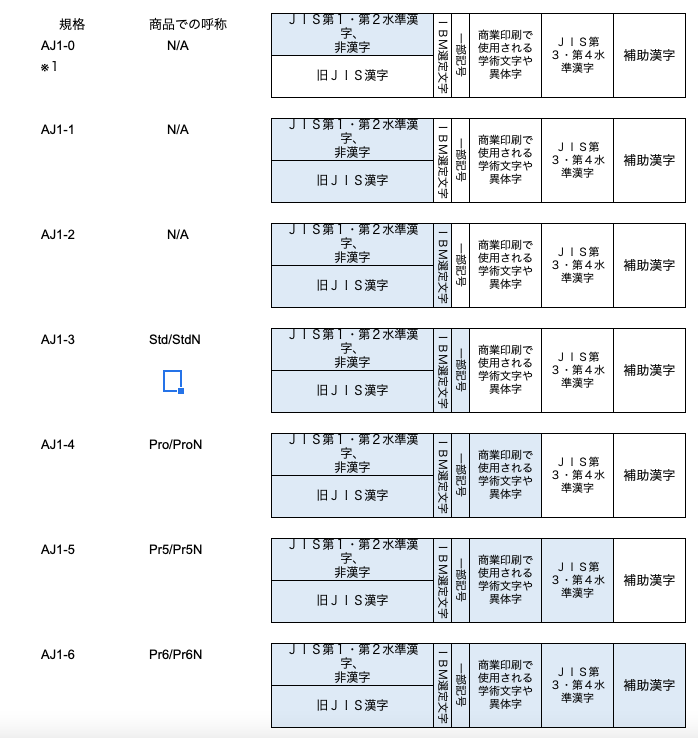
Adobeのフォントについての文字集合とグリフ定義
ここでPDFに戻ってフォントの指定を再度確認してみると、フォント指定が「KozGoPr6N-Medium」 となっていますから、文字集合 Adobe Japan1-6でJIS2004のグリフをサポートする小塚フォント が指定されていることがわかります。
小塚フォントはAdobe Readerに内蔵されているため、PDFの埋め込みフォントでなくても 必ず使えると想定して良いフォントです。
すると古いプログラムはJIS2004をサポートするフォントを指定しているのに、実際に表示される 文字はJIS90のグリフで表示されていると言うことになります。
単純に「指定したフォントが古くて古いグリフが表示されている」と言う問題ではなさそうです。
PDFの文字の表示方法
開き直って、PDFの文字の表示方法を調べてみました。
次のような仕組みでAdobe Readerはテキストからフォントのグリフを引き当てます。
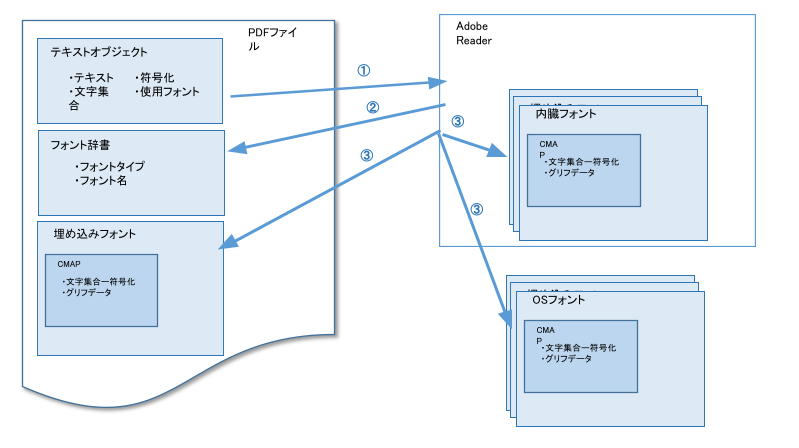
PDF フォント表示の仕組み
PDF内のテキストオブジェクトからテキスト、文字コード(文字集合、符号化)、使用フォント名を取得する。
取得した使用フォント名からフォント辞書を検索し、フォントを探す。
取得したフォント情報からフォントファイルを特定する。 この時、埋め込みフォント、Reader内蔵フォント、OSフォントなどが使用される。 テキストの文字コード(文字集合、符号化)からフォントファイルのCmapで合致する 文字コードのテーブルを選択し文字と実際のグリフの紐付けを取得し、グリフを表示する。
想像の結果
調査の結果、Macのプレビューでも同様にJIS90で表示されるという事がわかりました。 もちろん、プレビューはAdobe Reader内蔵の小塚フォントの位置を知りませんから、ヒラギノ・ フォントで表示されます。
こうなると、フォントの問題でなくPDFに指定された文字コードがどのように解釈され フォントに引き当てられるかという問題のような気がしてきました。
再度 PDFのプロパティを確認すると、エンコーディングが「90ms-RKSJ-H」となっています。
このエンコーディングの表記は、「文字セット-符号化方式-組み方向」を意味しています。
すると、このPDFは「Windowsでのマイクロソフトの文字セットでシフトJISで横書き」と言う意味となります。
確かに昔のPDFではこのエンコーディングはよく使われていました。しかし、2004年にグリフの変更がありフォントも対応しており変わっています。Adobe Readerのアプリ内のリソースを確認していくと、Adobe Reader内にもCmapを持っており、この中に90MS-RKSJ-Hもありました。
%!PS-Adobe-3.0 Resource-CMap %%DocumentNeededResources: ProcSet (CIDInit) %%IncludeResource: ProcSet (CIDInit) %%BeginResource: CMap (90msp-RKSJ-H) %%Title: (90msp-RKSJ-H Adobe Japan1 2) %%Version: 11.003
ここで Titleに注目です。Adobe Japan 1 2ですと!
具体的に文字コードとグリフのマッピングについて、複数のCMapで検証してみました。
「葛」という文字について調べてみました。
CMap |
定義 |
説明 |
|---|---|---|
90ms-RKSJ-H |
<8a80> <8afc> 1470 |
SJISで「葛」は8A8B。左は範囲を表していると思われるため、該当するグリフの番号は1481と思われる。 |
UniJIS-UCS2-H |
<845b> <845b> 1481 |
UCS2で「葛」は845B。グリフの番号は1481 |
UniJIS-UTF8-H |
<e8919b> 1481 |
UTF-8では、「葛」はE8919B。グリフ番号は1481 |
UniJIS2004-UTF8-H |
<e8919b> 7652 |
同じUTF-8でもJIS2004のCmapではグリフ番号は7652 |
UniJIS2004-UTF16-H |
<845b> 7652 |
JIS2004のUTF-16のCMapでは、グリフ番号は7652 |
UniJIS2004-UTF32-H |
<0000845b> 7652 |
JIS2004のUTF-32のCMapではグリフ番号は7652 |
UniJISX0213-UTF32-H |
<0000845b> 1481 |
JISX0213のUTF-32のCMapではグリフ番号は1481 |
UniJISX02132004-UTF32-H |
<0000845b> 7652 |
JISX0213:2004のUTF-32のCMapではグリフ番号は1481 |
なんとなく見えてきました。
結局、PDF生成時に指定されたエンコーディングからAdobe Readerは内部のCMapが選択し グリフの取得に使っているようです。Adobe Reader内には古いグリフとJIS2004以降のグリフの 2系統のCMap持っており、どちらが選択されたかでどちらの字形で表示されるか決まるようです。